Writing git hooks with Git::Hooks
Let's start with the hooks.
As a developer, you are probably using git for source control. And if you are using git, you are probably using git hooks too, even if you don't realize it! hooks are simply programs that git runs automatically whenever you do certain things in a git repo - for example, when you commit, or push, or merge code.
If you use some remote repository like GitHub or GitLab it is very likely you might actually be using git hooks installed by those services to rebuild web pages, trigger deployments or myriad other stuff. Both GitHub and GitLab allow us to configure them quite easily via the various web services' web interfaces.
However, the point of this article is to show you how to write them yourself, in your own local repos. With git hooks - and the power of Perl - we can do all kinds of automations making your life as a developer easier.
So let's first find out what kind of events can trigger a hook. The whole list is on the Git reference page and, in the last git version, includes 18 different events:
- applypatch-msg
- pre-applypatch
- post-applypatch
- pre-commit
- prepare-commit-msg
- commit-msg
- post-commit
- pre-rebase
- post-checkout
- post-merge
- pre-push
- pre-receive
- update
- post-receive
- post-update
- push-to-checkout
- pre-auto-gc
- post-rewrite
We can divide them in different ways; for instance, according to when they actually happen. You'll notice that a lot of these have names starting with pre and post. pre and post hooks are run before and after a particular git command does its normal operation respectively.
pre hooks can return a value that will effect the outcome of the git command, possibly indicating that the particular action has failed, and can be used to implement policies at the client level (for example, if a commit message contains typos or fails company policy in some other way a pre commit can stop the commit being actually committed.)
post hooks are the opposite: They do not affect the command itself, just the way the repository is arranged after the command is run. A post-receive hook, for instance, can send an email to the user or administrator when a push has been processed on a remote repository, or send a message to a continuous integration server to start a test run, or trigger a rebuild of the web site.
Hooks can also be divided according to the git command that triggers them. Four of them, are related to commit, others to am, and yet others to push and to receive-pack, a plumbing command run when a push is received in a repository.
Now that we mention plumbing
Writing hooks involves diving into the depths of git, going, so to say, into the plumbing. In fact, git commands are divided, using a washroom metaphor, into two classes: porcelain and plumbing. It is not too clear which is which, the division being "what can be seen from outside" (porcelain) and "what is used from there" (plumbing). According to that, most of the stuff we use day to day from the command line, clone, add, commit and so on, are "porcelain". And most of the stuff you do not usually run is plumbing: git-unpack-file or git-read-tree is not the kind of thing you usually run from the command line. However, these are precisely the kinds of commands we are going to run from our hooks.
And plumbing works on the pipes.
Or, actually, the trees. Let's again get back to basics and study the three states of a project in git: the working directory (also called the working tree), the staging area (also called the index), and the .git directory that contains everything we normally consider to be in the repository. In a nutshell, the git command add adds files to the staging area, the git command commit passes files from the staging area through to the .git directory, and the git command checkout takes files back from the .git directory to the working directory.
If we poke around inside the .git directory we see this plumbing area is full of trees. Trees are used to store directories with the files and other directories, also stored as trees, in them. This is an efficient, packed way of storing content; git is actually a content-addressable file system. Which is great. But takes us away from the simple concept of a-source-control-management-system-storing-changes-and-that's-it.
The good news about this is that git allows us to work easily, through plumbing commands, with the internal structure so we don't have to manipulate these trees directly. The bad news is that we pretty much need to know how to program our own git in order to write a good hook.
Writing our First Hook
As said above, hooks are simply scripts. They can be as simple as a shell script or as complicated as a REST client consuming an API. In general, a hook will work this way
- 1. Examine stuff
-
Look at what's going on. Examine its inputs and use them to dig a bit deeper using plumbing commands, set the stage.
- 2. Do Work
-
Do the real work. Change log messages, rearrange files or create new ones, do lots of different things.
- 3. Return
-
Return, possibly with a message, including a failure or success message if it is a
pre-class hook.
Let us see how it works in practice. Here is an example of a simple three line script that can serve as a prepare-commit-msg hook to add some text to our commit message:
lines_changed=$(git diff-index HEAD --cached -p | grep "^\+\w" | wc -l)
message="\nYou have changed $lines_changed lines"
grep -qs "^$message" "$1" || echo "$message" >> "$1"No Perl yet, but just wait there and you will see! To install this three line script as a hook the three lines should be saved as a file called prepare-commit-msg, that file needs to be chmod +x'ed to become executable, and finally that file must be placed into the .git/hooks directory.
By the way, you can find lots of other examples as gists of hooks to modify your commit message with Google.
Anyway, the first two lines of our example script compute first the number of lines changed. They use a plumbing command, git-diff-index. Following the online documentation this command
Compare[s] a tree to the working tree or indexWhich one are we doing here? Since we are using --cached we
compares the tree-ish and the index.In this case, HEAD (i.e. the last commit already previously committed) is the tree-ish thing we're comparing with the index (i.e. whatever files we have already added to this commit in the staging area). The -p option is putting everything in a patch format, something like:
diff --git a/2016/submission/git-hooks.pod b/2016/submission/git-hooks.pod
index 1fb44ed..1c8fc79 100644
--- a/2016/submission/git-hooks.pod
+++ b/2016/submission/git-hooks.pod
@@ -95,7 +95,7 @@ general, a hook will work this way
=item Check out stuff
- Look at what's going on. Check out its inputs and use them to
+Look at what's going on. Check out its inputs and use them to
dig a bit deeper using plumbing commands, set the stage.You will see a + sign, which indicates the lines that have been added. The grep pipe in our first line filters out everything but those lines and wc -l counts them. The next line will create a message to be added to the commit message, and the last line effectively does that, after checking that it is not already there (since we would not want multiple messages like that, ever). $1 will contain the name of the file that contains the commit message, generally COMMIT_MSG.
That's our script in its entirety. No big deal here...except that we need to know some stuff about Linux commands, its not going to be easy to debug, and as soon as we want something a bit more complex we are getting into sed and AWK terrain. And nobody wants that!
So let's do it in Perl
There are many ways of doing this in Perl (You didn't expect that, did you?)
First version would just move whatever is a bit more complicated to Perl itself. Let us run git as an external command, since that's seemingly our easiest option. Besides, now that we have a sensible language we might go a bit further and consider not only lines added, but also lines taken from the file. And we can do that not by counting lines with + at the front, but parsing the diff format which says how many lines have changed. The result is this program, a bit longish
#!/usr/bin/env perl
use strict;
use warnings;
use File::Slurp::Tiny qw(read_file write_file);
use v5.14;
my $commit_msg_fn = shift || die "No commit message file";
my $commit_msg = read_file( $commit_msg_fn );
die if !$commit_msg;
my $diff_output = `git diff-index HEAD --cached -p`;
my @lines_changed = ($diff_output =~ /-\d+,(\d+) \+\d*,?(\d+)/gs);
my ($lines_added, $lines_taken);
while ( @lines_changed ) {
$lines_taken += shift @lines_changed;
$lines_added += shift @lines_changed;
}
my $message="\nYou have added $lines_added and taken $lines_taken lines";
if ( $commit_msg !~ /$message/ ) {
write_file( $commit_msg_fn, $commit_msg.$message );
}That Perl script is pretty much what we did above in the smaller shell script. The results is more or less the same, and can be seen in action in the repo. But we are still not where we want to be.
Which perl are we running?
There is a caveat here in our script, and that is the env in the first line which causes whatever perl is first in our path to be executed.
From the shell I use a perl created with perlbrew, and use the perlbrew command to manipulate the shell PATH to run that perl. That path is not going to be available in this spawned shell that my git hook is running, meaning it will use the system perl. There are many solutions to this - including simply installing the modules you need for your git hooks on your system perl with `cpan` / `cpanm`.
Let's perlify it even more
The second, and more significant, problem is that running an external command brings all kind of trouble in particular setups. It is not Pure Perl either.
In fact, if you've got git, you've got a Perl way of doing git using a Perl module without having to directly script the git command ourselves. As part of the git distribution, a Git.pm file is directly installed in /usr/share/perl5 (at least in new versions of git.) perldoc Git will show you what to expect from it, and you can also check it out on MetaCPAN, although in fact it is developed (pretty much, it's kind of quiet) alongside git itself in its repository.
Be that as it may, Git.pm provides a Perl interface for running git. After adding use Git; at the beginning, we will insert these new two lines
my $repo = Git->repository();
my $diff_output = $repo->command('diff-index', '--cached','-p','HEAD');That is not buying us much, except, well, we are kind of less worried about running external commands from our program (which we are doing anyway, only kind of under the hood)
But now we have the full power of Perl
So let us use it for the greater good. For instance, it would be nice to prohibit anything that can't be compiled from being checked in. Many companies include pre-commit policies that check that, and a host of other things, there are whole frameworks that allow management of this kind of policies, like this one written in Python by Yelp. We might want to check that out later on (or not, because Not Perl), but meanwhile we can run a simple syntax check on the Perl files before they are even committed. This would do the trick:
#!/usr/bin/env perl
use strict;
use warnings;
use Git;
use Term::ANSIColor;
use v5.14;
my $repo = Git->repository();
my $diff_output = $repo->command('diff-index', '--cached','-p','HEAD');
my @files_changed = ($diff_output =~ /\++\sb\/(\S+)/gs);
my $syntax_ok = 0;
foreach my $file ( @files_changed ) {
next if ( $file !~ /\.p[ml]/ );
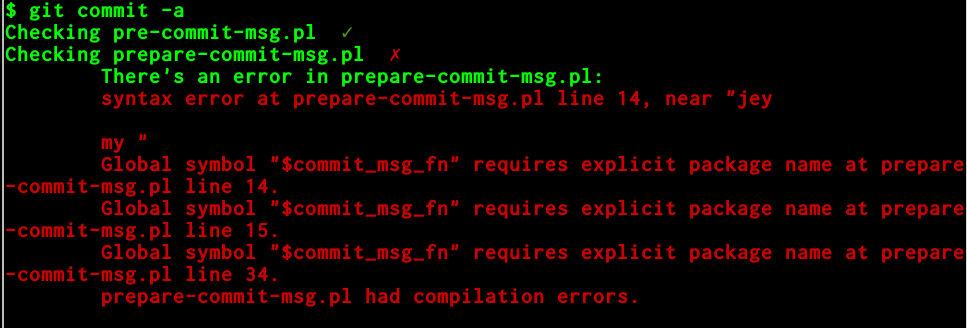
print "Checking $file ";
my $output = `perl -cw $file 2>&1`;
if ($output =~ /syntax error/ ) {
$syntax_ok = $syntax_ok || 1;
say color("red"), "\N{BALLOT X}", color("reset"),
"\n\tThere's an error in $file:", color("red"),
join("",map( "\n\t$_", split("\n",$output))), color("reset");
} else {
say color("green"),"\N{HEAVY CHECK MARK}", color("reset");
}
}
exit $syntax_ok;This script will be copied or symlinked to pre-commit in the hooks directory and will check syntax and warnings for any Perl file that has been modified during the commit. It uses the same git command as above for obtaining the files that have been modified, extracting the filenames from the diff output. That is why it is using:
($diff_output =~ /\++\sb\/(\S+)/gs);which will get filenames from lines such as this one
+++ b/2016/submission/git-hooks.pod(this will work as long as the filenames do not have any whitespace in them). Anyway for every file modified it will proceed to run perl-cw on it. If it passes muster, it will give the go ahead. If it does not, it will exit with a 1, which will indicate to git that the commit cannot proceed, printing at the same time the cause of the error.
We also add color for niceness, using the Term::ANSIColor module. One of the good things we can use within Perl. But we have also got even better things.
Enter Git::Hooks
Git::Hooks is written specifically to do this kind of thing. It lays a layer of goodness over other modules that deal with Git and allows us to work easily with the information that is available to us inside the hooks. Besides, and this is the nicest thing, it allows us to unify all hooks in a single script. Let's unify the two files we have above in a single one.
This is the one program to rule them all:
#!/usr/bin/env perl
use strict;
use warnings;
use Git::Hooks;
use Term::ANSIColor;
use File::Slurp::Tiny qw(read_file write_file);
use v5.14;
sub diff_output {
my $git = shift;
$git->command('diff-index', '--cached','-p','HEAD');
}
PRE_COMMIT {
my ($git) = @_;
my @files_changed = (diff_output( $git) =~ /\++\sb\/(\S+)/gs);
...the same pre-commit logic as in our script...
return $syntax_ok;
};
PREPARE_COMMIT_MSG {
my ($git, $commit_msg_fn) = @_;
my $commit_msg = read_file( $commit_msg_fn );
die if !$commit_msg;
my @lines_changed = (diff_output( $git ) =~ /-\d+,(\d+) \+\d*,?(\d+)/gs);
...the same prepare-commit-msg logic as in our other script...
};
run_hook($0, @ARGV);This is just part of the program; the rest is in the git-hooks repository. Git::Hooks has a centralized approach to hooks: it encourages you to create a single file, that is symlinked to the different hook names; in this case, prepare-commit-msg and pre-commit-msg. The magic is done by the last line containing run_hook which takes the command under which it is being invoked $0 along with the command-line arguments.
The hooks are declared LABEL-like (although they are actually function calls.) These calls receive always $git as the first argument, the git command itself. And its invocation is actually the same as we did before, only we have used a slightly different syntax via the qw quote operator. And we do that in the diff_output function, which is actually the only part where we are winning something by factoring out part of the code, this common code that includes the differences between the repository in the previous state and this one. A single file is easier to maintain and copy around; in fact, you can create a git directory template which includes this single file and its corresponding symlinks so that your development team plays by the hook. Pun intended.
Enforcing commit-refers-to-issue policies
An idea that I try to instill in my students is that you always work in a project towards an objective, and that objective must be engraved in a milestone (get it? Engraved... in a mile-stone), which must be divided in tasks that are assigned issues. This is such a dyed-in-the-wool thing that Git::Hooks has a plugin that checks that every commit message includes a valid JIRA issue. In fact, there are many off-the-shelf plug-ins that can be activated via the combination of git config variables and ready-to-go plug-ins. Other frameworks also including little-to-no-programming hooks for integration in development ecosystems.
However, we use plain old GitHub issues, and that is what we want to use: let's accept a commit message if and only if it addresses at least one valid issue. We will do this with that chunk of code, that is integrated along with the other hooks. Please go to the repo for the whole file, just the part including the new code has been included here.
COMMIT_MSG {
my ($git, $commit_msg_file) = @_;
my $git_repo = Git::More->repository();
my $api_key = $git_repo->get_config( 'github','apikey' );
my $gh = Net::GitHub->new(
version => 3,
access_token => $api_key
);
my $origin = $git_repo->get_config( 'remote.origin','url' );
my ( $user, $repo ) = ($origin =~ m{:(.+?)/(.+)\.git});
my $issue = $gh->issue();
my @these_issues = $issue->repos_issues( $user, $repo, { state => 'open'} );
my %issues_map;
for my $i ( @these_issues ) {
$issues_map{$i->{'number'}} = $i->{'title'};
}
my $commit_msg = read_file( $commit_msg_file );
my @issues = ($commit_msg =~ /\#(\d+)/g);
if ( !@issues ) {
say "This commit should address at least one issue";
return 0;
} else {
my $addresses_issue = 1;
for my $i ( @issues ) {
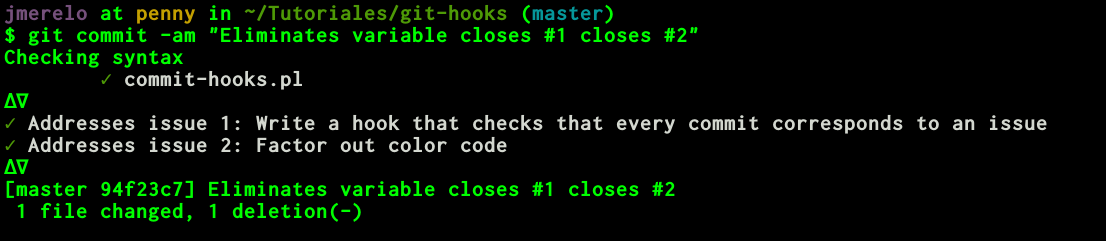
if ( $issues_map{$i} ) {
say pass("Addresses issue $i: $issues_map{$i}");
$addresses_issue &&= 1;
} else {
say fail("There is no issue $i");
$addresses_issue &&= 0;
}
}
say "\N{INCREMENT}\N{NABLA}";
return $addresses_issue;
}
};In order to use this, we will have first to create and copy an API key from GitHub. This key is going to be used to download the issues. After getting the API token from your profile, write
git config --add github.apikey abcdeandmanylettersmoreandnumbersSince we cannot pass through environment variables to the hooks, and it is really not a good idea to save the API key in a file, because you might accidentally add it to the repository, let's just handle it outside the repository by placing it in an environment that is available to the hooks: the git configuration file. We are going to be using Git::More, which is part of the Git::Hooks repository, to retrieve that key, which we do in
my $api_key = $git_repo->get_config( 'github','apikey' );We then use this key to open the API using yet another module, Net::GitHub. We will need this one to access the issues, which is something we do in the next few lines using the $issue->repos_issues function.
After that, the program creates a map with the issues (which makes them easier to check) and lets the commit pass if - and only if - there are issues and they actually exist and are open.
After hooking this hook by symlinking it to the script, the result will be something like this:
The tip of the hook
By itself, Perl is a great tool for writing git hooks. Together with the git and GitHub related modules, writing a set of hooks for your repositories is fast and straightforward. You might even not need to write anything, by just using Git::Hooks plugins.
Most difficult thing here is to debug the tools, but in many cases you will simply have to create a file with the right name and invoke the script with the right command line too, so that $0 and @ARGV are correct. Always bear in mind the environment in which the scripts are running, and before you know, you'll be hooked.
SEE ALSO
These are the modules that have been used here. There are hook frameworks in most other languages, some of them exclusively devoted to a particular hook. You might use them too if the language is already installed in your system.
* pre-commit in node.js, which can be configured via a JSON file.
POD ERRORS
Hey! The above document had some coding errors, which are explained below:
- Around line 10:
-
Cannot have multiple =encoding directives
Invalid =encoding syntax: utf8
 This article contributed by: JMERELO <JMERELO@cpan.org>
This article contributed by: JMERELO <JMERELO@cpan.org>