Have REST-ful Holidays
Have REST-ful Holidays
Your boss comes to you the day after Thanksgiving vacation (or if you're in Scotland, the day after St. Andrew's Bank Holiday; if you're not in Scotland or the US, adjust accordingly):
Boss: We need a Web API for the Flibber data. I want it to be REST-ful.
You: REST-ful API? Where did you hear about REST?
Boss: I've started reading /r/programming. Everyone is making REST APIs
now. We need one.
You: *sigh* I'll get right on that.So you need to build a REST-ful Web API in time for the Holidays. You may not even know what REST is, beyond some buzzword your boss picked up in an internet back-alley.
How to Explain REST to Anyone … even Ryan Tomayko's wife.
On Ryan Tomayko blog he has a dialog with his wife where he explains REST and why it's important. We really don't have time to go into all of the details so you should read it, but I'll try to cover the most important bits.
Ryan: [...] The web is built on an architectural style called REST. REST
provides a definition of a resource, which is what those things point
to.
Wife: A web page is a resource?
Ryan: Kind of. A web page is a representation of a resource. Resources are
just concepts. URLs--those things that you type into the browser...
Wife: I know what a URL is..
Ryan: Oh, right. Those tell the browser that there's a concept somewhere. A
browser can then go ask for a specific representation of the concept.
Specifically, the browser asks for the web page representation of the
concept.Basically the way the world wide web works is that clients request Representations of Resources identified by URLs (or URIs if you're pedantic). Clients and Servers use HTTP to give and return these requests. Most requests are by Browsers and they just want an HTML representation, but more and more clients are requesting non-HTML representations too. Thankfully the Web was designed to handle this, if we just write things in the right style.
REST is the style of writing applications so that they take full advantage of HTTP and the design of the Web. Now you know what REST is. Knowing is half the battle.
HTTP is Hard
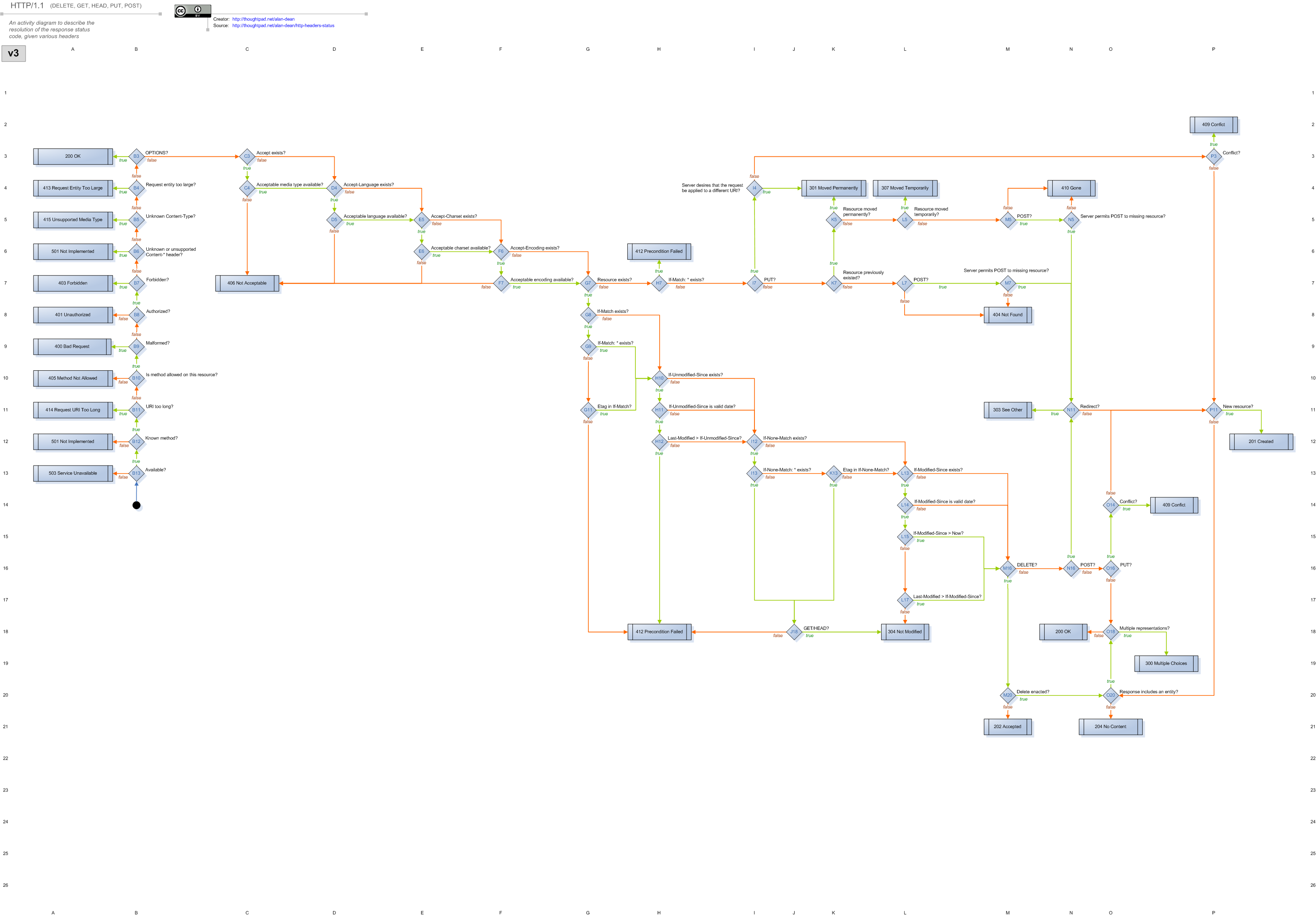
This is a diagram of the state machine based on the HTTP protocol. It has 57 states asking 50 different questions about how to process any given HTTP request and generate the right response. That's a lot to keep in your head.
Luckly there are frameworks on CPAN to help out with these. A good one for demonstrating these is Web::Machine by Stevan Little. It is based on the Erlang Webmachine project by Basho (makers of Riak!) that generated the state machine diagram.
Web::Machine is broken into two parts. A Finite State machine that implements the diagram, and a Resource base class that provides sensible defaults that you can override in your own class. Let's just dive in.
A note, while Web::Machine itself works on Perl 5.10.1 or higher, all examples will explicitly be using 5.16.2. Remember if you change the version line to enable strict.
It's a Time Machine!
So let's start with a basic web service. My Car doesn't have a clock in it, so to be properly Web 2.0 compliant, I'll write a JSON service that I can later target with an iOS client that will run from my phone. That won't be overkill at all.
use 5.16.2;
use Web::Machine;
{
package WasteOfTime::Resource;
use strict;
use warnings;
use parent 'Web::Machine::Resource';
use JSON::XS qw(encode_json);
sub content_types_provided { [{ 'application/json' => 'to_json' }] }
sub to_json { encode_json({ time => scalar localtime }) }
}
Web::Machine->new( resource => 'WasteOfTime::Resource' )->to_app;Web::Machine is a toolkit for building Resources. So after the standard boiler plate we start out by defining a resource class. Although Web::Machine was written by the same guy who brough you Moose it actually tries to be minimal about it's dependencies and doesn't sneak Moose in under the covers.
So we create a class WasteOfTime::Resource that will be our Resource class, and we have it inherit from Web::Machine::Resource so that Web::Machine will know it's a Resource and so that the proper defaults are set. We could be done here, and our application would do nothing but throw a 406 NOT ACCEPTABLE. But that's less than useful.
We know we want to provide a JSON API so we override the parent content_types_provided and say we will provide a representation of 'application/json' and that we should use the to_json method to get it.
Then we define the to_json representation. This resource doesn't have any state so we can just build the JSON inline. We use the scalar value of localtime because we want the nice string format not a list of numbers.
Finally once our resource class is built, we create a Web::Machine instance, tell it which resource class to use and then have it provide us a Plack application. If we save all of this in a file (I chose time.psgi) we can run it.
$ plackup time.psgi
HTTP::Server::PSGI: Accepting connections at http://0:5000/Which we can now access using a web client.
$ curl -v http://0:5000
* About to connect() to 0 port 5000 (#0)
* Trying 127.0.0.1... connected
* Connected to 0 (127.0.0.1) port 5000 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Date: Sun, 09 Dec 2012 02:04:02 GMT
< Server: HTTP::Server::PSGI
< Content-Length: 35
< Content-Type: application/json
<
* Closing connection #0
{"time":"Sat Dec 8 21:04:02 2012"}And you can see our Representation there at the end. If we try a request that isn't allowed, say for an HTML representation, we will get the appropriate error too.
$ curl -v http://0:5000 -H'Accept: text/html'
* About to connect() to 0 port 5000 (#0)
* Trying 127.0.0.1... connected
* Connected to 0 (127.0.0.1) port 5000 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: text/html
>
* HTTP 1.0, assume close after body
< HTTP/1.0 406 Not Acceptable
< Date: Sun, 09 Dec 2012 02:07:47 GMT
< Server: HTTP::Server::PSGI
< Content-Length: 14
<
* Closing connection #0
Not AcceptableWe get that 406 not acceptable again.
Many Ways to Say the Same Thing
So far we're not doing bad for 20 lines of code, but what if we want that HTML representation too? Actually it's pretty simple. First we add a new content type.
sub content_types_provided { [
{ 'application/json' => 'to_json' },
{ 'text/html' => 'to_html' },
] }We say that 'text/html' will be handled by to_html. Now we just define a to_html method to return our HTML representation.
sub to_html {
join "" =>
'<html>',
'<head>',
'<title>The Time Now Is:</title>',
'</head>',
'<body>',
'<h1>'.localtime.'</h1>',
'</body>',
'</html>'
}Notice that Web::Machine doesn't have any opinion on how you generate HTML. You're free to use whatever template system you want. You're also free to write all of the glue code for that. Web::Machine is pretty bare bones about that, this is why it's called a toolkit and not a framework.
So if we add this code and we issue that last request we can see the change.
$ curl -v http://0:5000 -H'Accept: text/html'
* About to connect() to 0 port 5000 (#0)
* Trying 0.0.0.0... connected
* Connected to 0 (0.0.0.0) port 5000 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: text/html
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Date: Sun, 09 Dec 2012 02:26:39 GMT
< Server: HTTP::Server::PSGI
< Vary: Accept
< Content-Length: 103
< Content-Type: text/html
<
* Closing connection #0
<html><head><title>The Time Now Is:</title></head><body><h1>Sat Dec 8 21:26:39 2012</h1></body></html>The Times They Are A Changing
So we're returning multiple representations, and that's great but what if we want to alter the resource? Let's let ourselves change the timezone. We'll need to use POSX qw(tzset) and add some methods.
use POSIX qw(tzset);
sub allowed_methods { [qw[ GET POST ]] }
sub process_post {
my $self = shift;
my $input = eval { JSON::XS->new->decode( $self->request->content ); };
$ENV{TZ} = $input->{timezone};
tzset;
return 1;
}Changing the allowed_methods lets Web::Machine know we are expecting POST requests as well as GET requests to this resource. Then when we process the post we simply set the appropriate value.
$ curl -v -X POST http://0:5000 -H 'Content-Type: application/json' -d '{"timezone":"America/Los_Angeles"}'
* About to connect() to 0 port 5000 (#0)
* Trying 127.0.0.1... connected
* Connected to 0 (127.0.0.1) port 5000 (#0)
> POST / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: */*
> Content-Type: application/json
> Content-Length: 34
>
* HTTP 1.0, assume close after body
< HTTP/1.0 204 No Content
< Date: Sun, 09 Dec 2012 02:49:22 GMT
< Server: HTTP::Server::PSGI
< Vary: Accept
< Content-Type: application/json
<
* Closing connection #0If we check now, we'll see that the time has changed.
$ curl -v http://0:5000
* About to connect() to 0 port 5000 (#0)
* Trying 127.0.0.1... connected
* Connected to 0 (127.0.0.1) port 5000 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Date: Sun, 09 Dec 2012 02:46:56 GMT
< Server: HTTP::Server::PSGI
< Vary: Accept
< Content-Length: 35
< Content-Type: application/json
<
* Closing connection #0
{"time":"Sun Dec 9 02:46:56 2012"}Since the previous times were America/New_York the new times are the correct 3 hours behind.
[Somethign Witty HERE]
In addition to supporting the standard HTTP methods, Web::Machine helps with much of the rest of the HTTP standard including things like Cache Control headers. To enable most basic cache controls simply provide a couple methods to generate ETag and last modified headers.
use Digest::SHA qw(sha1_hex);
use Web::Machine::Util qw(create_date);
sub generate_etag { sha1_hex(scalar localtime) }
sub last_modified { create_date(scalar localtime) }We import two new modules here. Digest::SHA helps us just make a unique identifier for our resource. Web::Machine::Util helps us create the appropriate date object that Web::Machine is expecting.
If we run our client against this now we'll see the new cache control headers.
$ curl -v http://0:5000
* About to connect() to 0 port 5000 (#0)
* Trying 0.0.0.0... connected
* Connected to 0 (0.0.0.0) port 5000 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Date: Sun, 09 Dec 2012 14:50:21 GMT
< Server: HTTP::Server::PSGI
< ETag: "fa4c7582066e3b42fffd346cfba9714ea66cd645"
< Vary: Accept
< Content-Length: 35
< Content-Type: application/json
< Last-Modified: Sun, 09 Dec 2012 14:50:21 GMT
<
* Closing connection #0
{"time":"Sun Dec 9 09:50:21 2012"}And if we make a request for a resource that should be cached, we get the right response code.
$ curl -v http://0:5000 -H'If-Modified-Since: Sun, 09, Dec 2012 14:55:21 GMT'
* About to connect() to 0 port 5000 (#0)
* Trying 0.0.0.0... connected
* Connected to 0 (0.0.0.0) port 5000 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5
> Host: 0:5000
> Accept: */*
> If-Modified-Since: Sun, 09, Dec 2012 14:55:21 GMT
>
* HTTP 1.0, assume close after body
< HTTP/1.0 304 Not Modified
< Date: Sun, 09 Dec 2012 14:55:11 GMT
< Server: HTTP::Server::PSGI
< ETag: "f6da728260ea1563bd14ce999f0246a4817f6fee"
< Vary: Accept
< Last-Modified: Sun, 09 Dec 2012 14:55:11 GMT
<
* Closing connection #0In addition to cache controls, Web::Machine provides methods for authentication, request validation, URI validation, charset and encoding variation, and most of the rest of the HTTP spec.
The Downsides
Web::Machine is pretty bare bones. It leaves a lot of opinions beyond HTTP up to the author. This is considered a bonus because these opinions are very much influenced heavily by the environment your application will be deployed in. If you want a framework that provides more pre-built wheels you may want to look at Magpie which is a framework based upon the same principles as Web::Machine but takes a very different approach for it's implementation.
One of the principles of REST is that hypertext is the engine of application state. Because Web::Machine has no opinions on templating, or really representation generation at all, it has no tools for building Hypermedia Documents. I highly recomend looking at the Hypermedia Application Language (HAL) specification for structuring hypermedia documents. It describes serializations in both JSON and XML depending on how old school you want to go.
Currently Web::Machine also doesn't handle an asynchronous environment. To be honest HTTP really doesn't have an asynchronous mode. The closest HTTP has is multi-part responses which are uni-directional streams. An example of this is the Twitter streaming API. There has been talk about adding support for this to Web::Machine but if you're looking for this, or something like Websockets right now, Web::Machine isn't the right choice.
See Also
 This article contributed by: Chris Prather <chris@prather.org>
This article contributed by: Chris Prather <chris@prather.org>